
SGLang Code Walkthrough
Paged KV Cache, Radix Attention, and FlashInfer


LLM inference engine consists of three layers
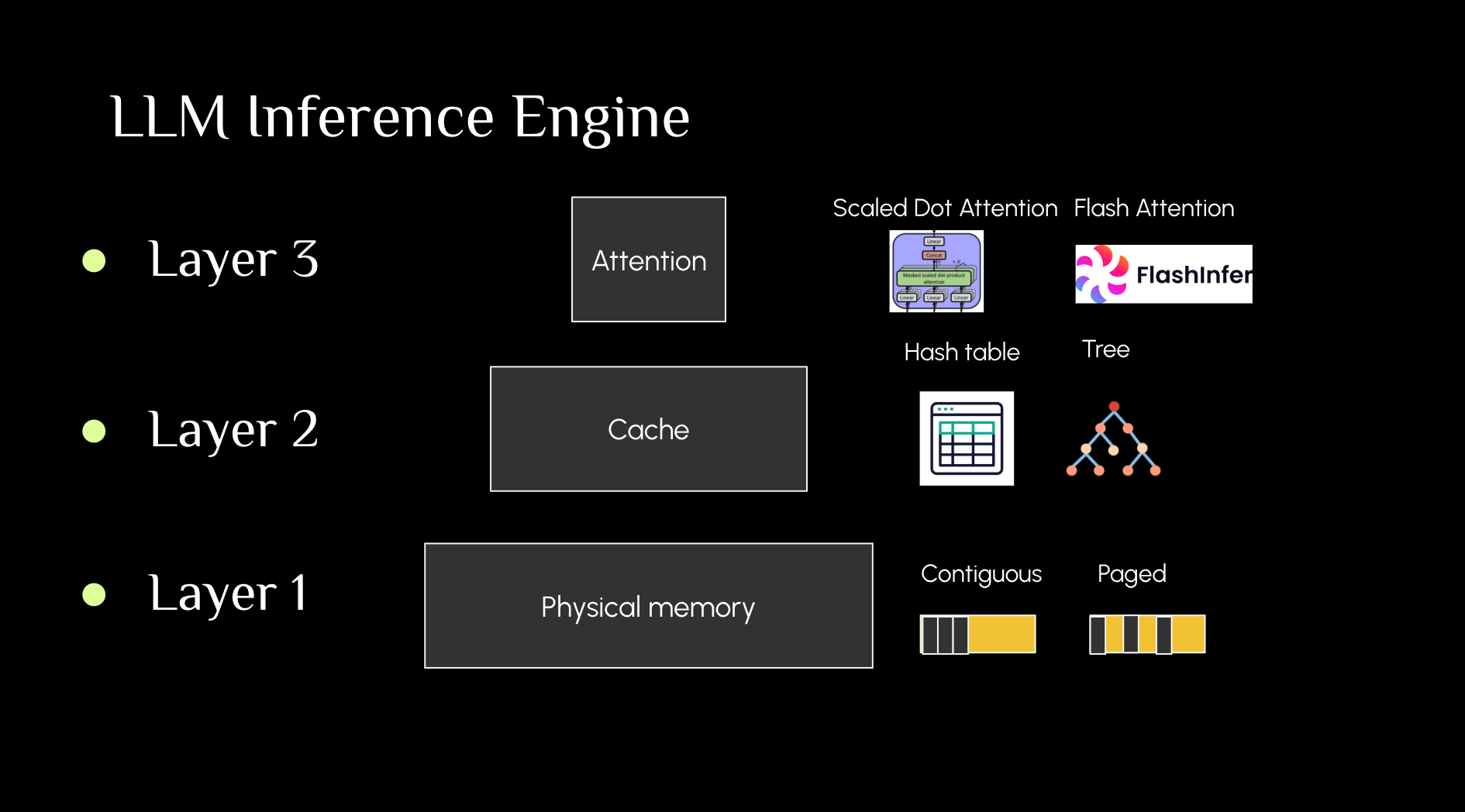
Part 1: Paged KV Cache - physical memory storage
Reference: Inside vllm: https://www.aleksagordic.com/blog/vllm
Part 2: Radix attention - virtual KV cache management
References:
Dynamo latest raod map
Github materials: https://github.com/sgl-project/sgl-learning-materials/blob/main/slides/sglang_pytorch_china_2025.pdf
Zhihu: https://www.zhihu.com/column/c_1710767953182674944
Best serving practice SGLang blog: https://lmsys.org/blog/2025-09-26-sglang-ant-group/
Part 3: FlashInfer
Block sparse: https://developer.nvidia.com/blog/accelerating-matrix-multiplication-with-block-sparse-format-and-nvidia-tensor-cores/